

“Change is not only likely, it’s inevitable.” – Barbara Sher
What is Data Shift or Data Drift?
Given human nature, it is very natural that the data we collect will change over time. Changes in data such as behavior and preferences are fast and drastic. It is even more relevant today with the impact of the Covid-19 pandemic making unprecedented changes to businesses. For a data science practitioner, the stability of data and its source are salient to develop and maintain robust ML (machine learning) solutions. Changes or drift in data will degrade the performance of predictive models.
From an ML perspective, the primary focus of data drift analysis is to detect the changes in the underlying distribution of independent (input to ML models) and dependent (target event for prediction) variables over time.
Concept drift refers to changes observed in the statistical properties of the target / dependent variable over time. It also signifies the shift in the relationship between the independent variables and target.
Covariate shift is a specific type of dataset shift when the distribution of the input (independent) variables changes between training and production environment.
Importance of Data Shift
Data has grown exponentially over the last decade, and our world is rooted in all sorts of data. Along with the explosion of data, the rapid advancements with ML algorithms have made AI (Artificial Intelligence) the backbone of industries across the globe. Machine learning has fundamentally changed the characteristics of the current decision-making process. The pace and ingenuity of business decisions have leapfrogged by using the right AI solutions. In pursuit of excellence, businesses are in constant need of data that is reliable and recent. Drift in data can pose serious challenges or even break the strategic decision-making process.
Concept drift could be indicating business changes, and it can have a significant impact on the performance of models that are in production. Covariate shift is more common and is likely to influence the distribution of risk scores, especially the proportion of predefined risk labels or buckets. The drastic and unforeseen changes in human and institutional behavior brought on by Covid-19 will have a considerable impact on predictive models as they rely heavily on historical data to inform their predictions. It’s an extreme case of concept drift, where the fundamentals are transformed or even entirely reformed. A few examples were sudden changes observed during 2020 & 2021 to previous years.
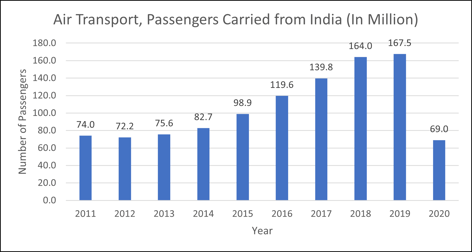
#1 The year 2020 was the worst year on record for the airline industry. Covid-19 resulted in a ~70% reduction in passenger revenues globally.
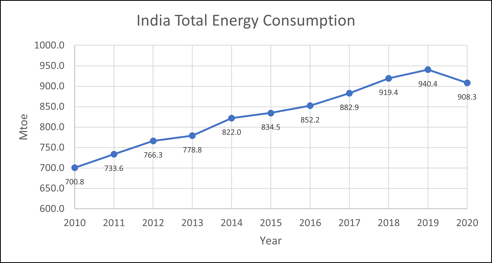
#2 Due to the Covid-19 crisis, total energy consumption in India fell by 3.4% in 2020 to 908 Mtoe. Over 2010-2019, it increased rapidly (+3.3%/year).
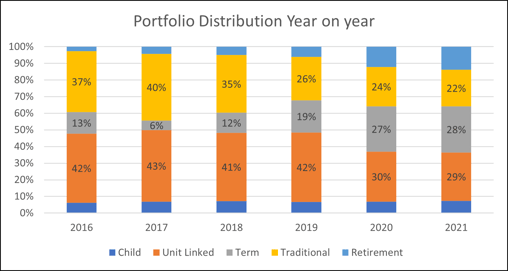
 #3 The portfolio distribution of one of the largest insurers in India show a change in customer priorities with the onset of Covid-19. There was a reduction in the proportion of market-linked (Unit Linked) products and an increase in the sale of Term products.
#3 The portfolio distribution of one of the largest insurers in India show a change in customer priorities with the onset of Covid-19. There was a reduction in the proportion of market-linked (Unit Linked) products and an increase in the sale of Term products.
How to Identify Data Shift?
Model monitoring is critical to detect data shift. The impact of Covid-19 has accelerated the need for proper and continuous monitoring of ML models. Model drift has real-world consequences, and its effect can be extremely severe if not identified and remediated quickly. Consider the critical supply shortages observed across the globe due to pre-Covid data models feeding projections & forecasting to the decision-making process.
Data drift is detected when continuous monitoring of the accuracy and performance of an ML model shows deteriorating indicators over time. If the average confidence of predicted scores changes over time, it also indicates concept drift. Since both concept drift and covariate drift involve a statistical change in data, continuous monitoring of the statical properties of input variables, model predictions, and their correlation is required to detect data drift.
Common statistical methods such as those listed below identify drift by comparing the difference between 2 populations.
Other statistical methods use a sequential algorithmic approach like Drift Detection Method (DDM) (Gama J. , Medas, Castillo, & Rodrigues, 2004), the Early Drift Detection Method (EDDM) (Baena-Garcia, et al., 2006), a drift detection method based on Geometric Moving Average Test (Roberts, 2000) and the Exponentially Weighted Moving Average Chart Detection Method (EWMAChartDM) (Del Castillo, 2001) (Ross, Adams, Tasoulis, & Hand, 2012).
ML model-based drift detection methods use a custom model designed to identify drift. An example is creating a binary classification model to distinguish datasets from two different time windows. The predictive power shown by the model will indicate the severity of data drift across these time windows, and the top predictors will capture the variables/predictors with maximum drift.
How to Manage the Shift in Data?
Businesses need to develop ML solutions that are drift-aware systems and are structured to address and accommodate changes in data.
Selection and Design of Input Predictors
The negative impact of data shift on ML models can be limited to a certain extent using the right set of features or input predictors:
Selection of Static Predictors - Modelers should avoid using predictors, especially static ones prone to changes. For example, predictors like product code, pin code, sales manager ID are bound to have sudden variations in their distribution over time. Models using such predictors are ill-prepared to handle changes that result in new products or sales from new pin codes or the hiring of new sales managers. In general, avoid predictors having a high likelihood to vary over time.
Design Predictors That are Resilient to Data Drift - Using derived time-dependent predictors can limit the influence of data drift. For example, instead of using pin code as an input predictor, create pin code-based pseudo markers like count of policies issued from pin code during last t years, % of policies issued from pin code with customer aged below 35, % of policies issued from pin code of a specific product type, the ratio of % of claims from pin code during last six months to % of claims from pin code during last t years. These time-dependent predictors do not completely shield the negative impact of data drift, but these predictors make ML models less vulnerable to sudden changes by capturing changing trends.
Model Retraining
Simple retraining of ML models on recent data is a common choice to handle challenges from deteriorating performance due to data drift. There are multiple ways of handling the retraining process. It could be as simple as retraining the model on the latest data window, collecting samples where data drift is identified and appending it to the training dataset, training a new model on the latest data, and creating an ensemble model with a production model, and so on.
Continuous Learning Models
Continual learning (CL) is an architecture capable of learning continually from a continuous data stream. This capability is one of the fundamental steps towards Artificial General Intelligence (AGI). These ML models can learn autonomously and continuously adapt based on new observations. It mimics the human learning process, knowledge transfer, and fine-tuning based on recent or unseen events.
With a proper framework to monitor data drift and subsequent model retraining, businesses can handle issues stemming from data drift. However, the impact of black swan events like Covid-19 might warrant a complete overhaul of ML models.
Conclusion
Data science teams often evaluate production models at fixed intervals or on an ad-hoc basis and do not actively monitor drift in data or model predictions. Continuous monitoring is required to detect all types of data drift and performance degradation on live models. Organizations should start building processes and tools for dedicated model monitoring, automated drift detection, retraining & testing, and deploying an updated model. It would require data science expertise and data engineering skillsets to automate and monitor production pipelines in a sustainable, systematic way. It will provide businesses the confidence in their decision-making process and the ability to deal with all types of data drift in the wake of unprecedented events.
Find out how Aureus data scientists are dealing with data drifts and ensuring the predictive power of machine learning models.

