

The field of artificial intelligence has always envisioned machines being able to mimic the functioning and abilities of the human mind. Language is considered as one of the most significant achievements of humans that has accelerated the progress of humanity. So, it is not a surprise that there is plenty of work being done to integrate language into the field of artificial intelligence in the form of Natural Language Processing (NLP). Today we see the work being manifested in likes of Alexa and Siri.
NLP primarily comprises of natural language understanding (human to machine) and natural language generation (machine to human). This article will mainly deal with natural language understanding (NLU). In recent years there has been a surge in unstructured data in the form of text, videos, audio and photos. NLU aids in extracting valuable information from text such as social media data, customer surveys, and complaints.
Consider the text snippet below from a customer review of a fictional insurance company called Rocketz Auto Insurance Company:
The customer service of Rocketz is terrible. I must call the call center multiple times before I get a decent reply. The call center guys are extremely rude and totally ignorant. Last month I called with a request to update my correspondence address from Brooklyn to Manhattan. I spoke with about a dozen representatives – Lucas Hayes, Ethan Gray, Nora Diaz, Sofia Parker to name a few. Even after writing multiple emails and filling out numerous forms, the address has still not been updated. Even my agent John is useless. The policy details he gave me were wrong. The only good thing about the company is the pricing. The premium is reasonable compared to the other insurance companies in the United States. There has not been any significant increase in my premium since 2015.
Let’s explore 5 common techniques used for extracting information from the above text.
1. Named Entity Recognition
The most basic and useful technique in NLP is extracting the entities in the text. It highlights the fundamental concepts and references in the text. Named entity recognition (NER) identifies entities such as people, locations, organizations, dates, etc. from the text.
NER output for the sample text will typically be:
Person: Lucas Hayes, Ethan Gray, Nora Diaz, Sofia Parker, John
Location: Brooklyn, Manhattan, United States
Date: Last month, 2015
Organization: Rocketz
NER is generally based on grammar rules and supervised models. However, there are NER platforms such as open NLP that have pre-trained and built-in NER models.
2. Sentiment Analysis
The most widely used technique in NLP is sentiment analysis. Sentiment analysis is most useful in cases such as customer surveys, reviews and social media comments where people express their opinions and feedback. The simplest output of sentiment analysis is a 3-point scale: positive/negative/neutral. In more complex cases the output can be a numeric score that can be bucketed into as many categories as required.
In the case of our text snippet, the customer clearly expresses different sentiments in various parts of the text. Because of this, the output is not very useful. Instead, we can find the sentiment of each sentence and separate out the negative and positive parts of the review. Sentiment score can also help us pick out the most negative and positive parts of the review:
Most negative comment: The call center guys are extremely rude and totally ignorant.
Sentiment Score: -1.233288
Most positive comment: The premium is reasonable compared to the other insurance companies in the United States.
Sentiment Score: 0.2672612
Sentiment Analysis can be done using supervised as well as unsupervised techniques. The most popular supervised model used for sentiment analysis is naïve Bayes. It requires a training corpus with sentiment labels, upon which a model is trained which is then used to identify the sentiment. Naive Bayes is not the only tool out there - different machine learning techniques like random forest or gradient boosting can also be used.
The unsupervised techniques also known as the lexicon-based methods require a corpus of words with their associated sentiment and polarity. The sentiment score of the sentence is calculated using the polarities of the words in the sentence.
3. Text Summarization
As the name suggests, there are techniques in NLP that help summarize large chunks of text. Text summarization is mainly used in cases such as news articles and research articles.
Two broad approaches to text summarization are extraction and abstraction. Extraction methods create a summary by extracting parts from the text. Abstraction methods create summary by generating fresh text that conveys the crux of the original text. There are various algorithms that can be used for text summarization like LexRank, TextRank, and Latent Semantic Analysis. To take the example of LexRank, this algorithm ranks the sentences using similarity between them. A sentence is ranked higher when it is similar to more sentences, and these sentences are in turn similar to other sentences.
Using LexRank, the sample text is summarized as: I have to call the call center multiple times before I get a decent reply. The premium is reasonable compared to the other insurance companies in the United States.
4. Aspect Mining
Aspect mining identifies the different aspects in the text. When used in conjunction with sentiment analysis, it extracts complete information from the text. One of the easiest methods of aspect mining is using part-of-speech tagging.
When aspect mining along with sentiment analysis is used on the sample text, the output conveys the complete intent of the text:
Aspects & Sentiments:
- Customer service – negative
- Call center – negative
- Agent – negative
- Pricing/Premium – positive
5. Topic Modeling
Topic modeling is one of the more complicated methods to identify natural topics in the text. A prime advantage of topic modeling is that it is an unsupervised technique. Model training and a labeled training dataset are not required.
There are quite a few algorithms for topic modeling:
- Latent Semantic Analysis (LSA)
- Probabilistic Latent Semantic Analysis (PLSA)
- Latent Dirichlet Allocation (LDA)
- Correlated Topic Model (CTM).
One of the most popular methods is latent Dirichlet allocation. The premise of LDA is that each text document comprises of several topics and each topic comprises of several words. The input required by LDA is merely the text documents and the expected number of topics.
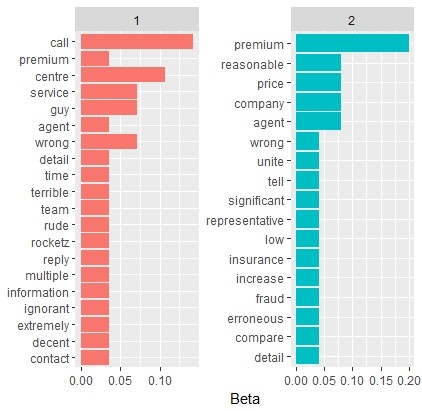
Using the sample text and assuming two inherent topics, the topic modeling output will identify the common words across both topics. For our example, the main theme for the first topic 1 includes words like call, center, and service. The main theme in topic 2 are words like premium, reasonable and price. This implies that topic 1 corresponds to customer service and topic two corresponds to pricing. The diagram below shows the results in detail.
Conclusion
These are just a few techniques of natural language processing. Once the information is extracted from unstructured text using these methods, it can be directly consumed or used in clustering exercises and machine learning models to enhance their accuracy and performance.
